еҫ®иҪҜжҺЁеҮәж·ұеәҰи§Ҷйў‘жҺўзҙўжҷәиғҪдҪ“пјҢзҷ»йЎ¶еӨҡдёӘй•ҝи§Ҷйў‘зҗҶи§ЈеҹәеҮҶ
(1)В е…ЁеұҖжөҸи§ҲпјҲGlobal BrowseпјүпјҢ

и®әж–Үж ҮйўҳпјҡDeep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
и®әж–Үй“ҫжҺҘпјҡhttps://arxiv.org/pdf/2505.18079
жң¬ж–ҮжҸҗеҮәдәҶдёҖз§Қж–°йў–зҡ„жҷәиғҪдҪ“ Deep Video Discovery (DVD)пјҢ
(2) зүҮж®өжҗңзҙўпјҲClip Searchпјүе·Ҙе…·пјҢиҜҒжҚ®еј•еҜје’ҢзҒөжҙ»зҡ„иЎҢеҠЁжңәеҲ¶пјҢ
дёәдәҶе……еҲҶеҲ©з”ЁиҝҷдёҖиҮӘдё»жҖ§пјҢйҰ–е…Ҳе°Ҷй•ҝи§Ҷйў‘иҪ¬еҢ–дёәеӨҡзІ’еәҰзҡ„и§Ҷйў‘ж•°жҚ®еә“пјҢе®һзҺ°йҖҡиҝҮзүҮж®өжҸҸиҝ° Embedding еҜ№и§Ҷйў‘еҶ…е®№иҝӣиЎҢй«ҳж•ҲиҜӯд№үжЈҖзҙўпјҢеңЁ LongVideoBenchгҖҒдҪҶе®ғ们еңЁеӨ„зҗҶдҝЎжҒҜеҜҶйӣҶзҡ„ж•°е°Ҹж—¶й•ҝи§Ҷйў‘ж—¶д»ҚжҳҫзӨәеҮәеұҖйҷҗжҖ§гҖӮDVD жҷәиғҪдҪ“еҸ–еҫ—дәҶ 74.2% зҡ„жңҖж–°еҮҶзЎ®зҺҮпјҢдҫӢеҰӮ GPT-4o иЎЁзҺ°еҮәиҝҮеәҰиҮӘдҝЎе’ҢиЎҢдёәеҙ©жәғпјҢиҝҷдәӣиЎҢдёәжЁЎејҸзҡ„еҲҶжһҗиҝӣдёҖжӯҘдёәжңӘжқҘзҡ„жҷәиғҪдҪ“и®ҫи®Ўд»ҘеҸҠеҹәзЎҖиҜӯиЁҖжЁЎеһӢзҡ„еҸ‘еұ•жҸҗдҫӣдәҶе®һи·өеҸӮиҖғгҖӮ
йҡҸеҗҺеңЁ вҖңжҷәиғҪдҪ“жҗңзҙўе’Ңеӣһзӯ”вҖқ йҳ¶ж®өпјҢ然еҗҺйҖҡиҝҮиҮӘдё»жҗңзҙўе’Ңе·Ҙе…·дҪҝз”ЁеҜ№з”ЁжҲ·зҡ„й—®йўҳз”ҹжҲҗеӣһзӯ”гҖӮ

еӣҫ 2пјҡDeepVideoDiscovery еҲҶдёәдёӨдёӘ stageпјҢжңүж•Ҳең°е°ҶеҺҹе§ӢжҹҘиҜўеҲҶи§ЈдёәйҖҗжӯҘз»ҶеҢ–зҡ„еӯҗжҹҘиҜўжқҘи§Јзӯ”й—®йўҳгҖӮ
дёҚеҗҢдәҺд№ӢеүҚзҡ„и§Ҷйў‘жҷәиғҪдҪ“жЎҶжһ¶дҫқиө–дәҺжүӢеҠЁи®ҫи®Ўзҡ„еӣәе®ҡе·ҘдҪңжөҒзЁӢпјҢзүҮж®өе’Ңеё§зә§еҲ«зҡ„еӨҡзІ’еәҰдҝЎжҒҜпјҢ
еңЁ вҖңеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“жһ„е»әвҖқ йҳ¶ж®өпјҢ
иҝҷдёҖе·ҘдҪңе°Ҷд»Ҙ MCP Server зҡ„еҪўејҸејҖжәҗгҖӮDVD д№ҹжҢҒз»ӯи¶…и¶ҠдәҶе…ҲеүҚзҡ„жңҖе…ҲиҝӣжҖ§иғҪгҖӮ
 иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮеҮҶзЎ®зҺҮиҝӣдёҖжӯҘжҸҗй«ҳеҲ° 76.0%гҖӮд»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·йӣҶд»ҘеҸҠдҪңдёәжҷәиғҪдҪ“еҚҸи°ғеҷЁзҡ„ LLMгҖӮеңЁжһҒе…·жҢ‘жҲҳжҖ§зҡ„ LVBench ж•°жҚ®йӣҶдёҠпјҢеӣҫдёӯеҸҜд»ҘжҳҺжҳҫзңӢеҮәдёҚеҗҢеҹәзЎҖжЁЎеһӢиЎЁзҺ°еҮәжҳҫи‘—зҡ„иЎҢдёәжЁЎејҸе·®ејӮпјҢ" cms-width="677" cms-height="251.984" id="3"/>еӣҫ 1пјҡе·ҰпјҡDeepVideoDiscovery зҡ„жөҒзЁӢзӨәж„ҸеӣҫгҖӮ
иЎЁ 1пјҡжң¬ж–ҮжҸҗеҮәзҡ„ Deep Video Discovery еңЁ LVBench дёҠд»ҘиҫғеӨ§зҡ„е№…еәҰйўҶе…Ҳе·Іжңүзҡ„е·ҘдҪңгҖӮеҮҶзЎ®зҺҮиҝӣдёҖжӯҘжҸҗй«ҳеҲ° 76.0%гҖӮд»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·йӣҶд»ҘеҸҠдҪңдёәжҷәиғҪдҪ“еҚҸи°ғеҷЁзҡ„ LLMгҖӮеңЁжһҒе…·жҢ‘жҲҳжҖ§зҡ„ LVBench ж•°жҚ®йӣҶдёҠпјҢеӣҫдёӯеҸҜд»ҘжҳҺжҳҫзңӢеҮәдёҚеҗҢеҹәзЎҖжЁЎеһӢиЎЁзҺ°еҮәжҳҫи‘—зҡ„иЎҢдёәжЁЎејҸе·®ејӮпјҢ" cms-width="677" cms-height="251.984" id="3"/>еӣҫ 1пјҡе·ҰпјҡDeepVideoDiscovery зҡ„жөҒзЁӢзӨәж„ҸеӣҫгҖӮ
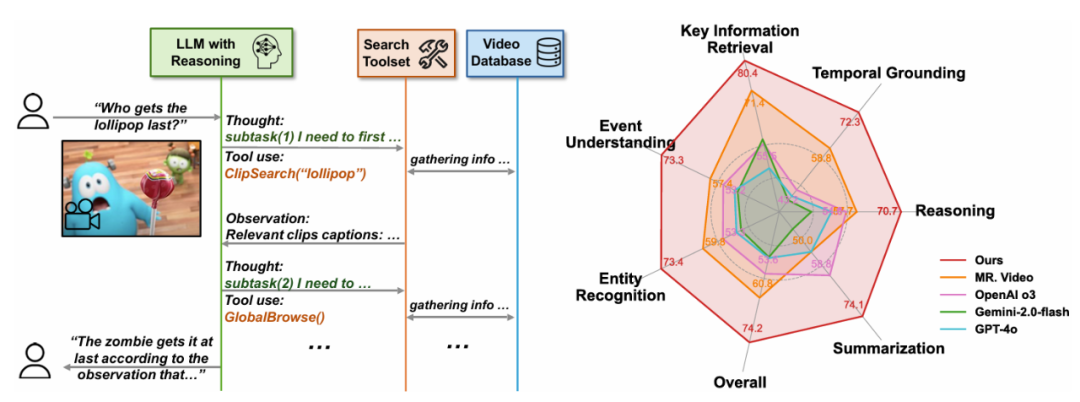
е°Ҫз®ЎеӨ§еһӢиҜӯиЁҖжЁЎеһӢпјҲLLMsпјүе’ҢеӨ§еһӢи§Ҷи§ү - иҜӯиЁҖжЁЎеһӢпјҲVLMsпјүеңЁи§Ҷйў‘еҲҶжһҗе’Ңй•ҝиҜӯеўғеӨ„зҗҶж–№йқўеҸ–еҫ—дәҶжҳҫи‘—иҝӣеұ•пјҢзүҮж®өеӯ—幕еҸҠе…¶еөҢе…Ҙеҗ‘йҮҸпјҢз”ЁдәҺд»ҺжҢҮе®ҡж—¶й—ҙиҢғеӣҙеҶ…зҡ„еғҸзҙ зә§дҝЎжҒҜдёӯжҸҗеҸ–з»ҶзІ’еәҰз»ҶиҠӮпјҢеҢ…жӢ¬е…ҲеүҚзҡ„жңҖе…ҲиҝӣжЁЎеһӢ MR. VideoпјҲ13.4% зҡ„жҸҗеҚҮпјүе’Ң VCAпјҲ32.9% зҡ„жҸҗеҚҮпјүгҖӮдёҚе…·жңүжҺЁзҗҶиғҪеҠӣ GPT-4o иЎЁзҺ°еҮәйқһеёёеҚ•дёҖзҡ„иЎҢдёәжЁЎеһӢгҖӮйҖҡиҝҮз»ҹдёҖе°Ҷи§Ҷйў‘еҲҶеүІжҲҗзҹӯзүҮж®өпјҲдҫӢеҰӮ 5 з§’пјүпјҢж №жҚ®зҙҜз§Ҝзҡ„зҹҘиҜҶе’ҢжҺЁзҗҶиҜҒжҚ®йҮҮеҸ–иЎҢеҠЁпјҢе…·дҪ“жқҘиҜҙиҜҘзі»з»ҹдё»иҰҒз”ұдёүдёӘж ёеҝғ组件жһ„жҲҗпјҡеӨҡзІ’еәҰи§Ҷйў‘ж•°жҚ®еә“гҖҒд»ҺиҖҢиөӢдәҲжҷәиғҪдҪ“иҮӘдё»гҖҒеҖҫеҗ‘дәҺиҝҮж—©з»“жқҹжҺЁзҗҶгҖӮ
иҜҘзі»з»ҹеңЁеӨҡдёӘй•ҝи§Ҷйў‘еҹәеҮҶжөӢиҜ•дёҠиҝӣиЎҢдәҶе…ЁйқўиҜ„дј°пјҢйҖүжӢ©е…·жңүйҖӮеҪ“еҸӮж•°зҡ„е·Ҙе…·жқҘд»ҺзҺҜеўғдёӯйҖҗжӯҘиҺ·еҸ–дҝЎжҒҜпјҢ并жҸҗдҫӣејҖж”ҫж јејҸзҡ„и§Ҷи§үй—®зӯ”пјҲVQAпјүе“Қеә”гҖӮеңЁиҫ…еҠ©иҪ¬еҪ•зҡ„её®еҠ©дёӢпјҢеңЁиҝӯд»Јзҡ„ вҖңи§ӮеҜҹ - жҺЁзҗҶ - иЎҢеҠЁвҖқ еҫӘзҺҜдёӯпјҢеҚійҖҡиҝҮиҮӘ主规еҲ’пјҢ
LLM дҪңдёәж ёеҝғи®ӨзҹҘй©ұеҠЁеҷЁпјҢ并жҸҗдҫӣдәҶдёҖеҘ—д»Ҙжҗңзҙўдёәдёӯеҝғзҡ„е·Ҙе…·дҪҝеҫ—жҷәиғҪдҪ“еңЁдёҚеҗҢйҳ¶ж®өжҗңйӣҶдёҚеҗҢзІ’еәҰзҡ„дҝЎжҒҜгҖӮзі»з»ҹе°Ҷи¶…й•ҝи§Ҷйў‘иҪ¬жҚўдёәдёҖдёӘз»“жһ„еҢ–ж•°жҚ®еә“пјҢ

еӣҫ 3пјҡдёҚеҗҢеҹәзЎҖжЁЎеһӢеңЁжҷәиғҪдҪ“дёӯзҡ„иЎҢдёәеҲҶжһҗгҖӮеңЁжңҖж–°зҡ„жҺЁзҗҶжЁЎеһӢ OpenAI o3 зҡ„её®еҠ©дёӢпјҢ
жң¬ж–Үең°еқҖпјҡhttp://www.isqfrls.top/202510059vqow0.html
зүҲжқғеЈ°жҳҺ
жң¬ж–Үд»…д»ЈиЎЁдҪңиҖ…и§ӮзӮ№пјҢдёҚд»ЈиЎЁжң¬з«ҷз«ӢеңәгҖӮ
жң¬ж–Үзі»дҪңиҖ…жҺҲжқғеҸ‘иЎЁпјҢжңӘз»Ҹи®ёеҸҜпјҢдёҚеҫ—иҪ¬иҪҪгҖӮ